Reducing inequality in forest research through cyber-innovated global partnerships
Amidst the trees, a world alive,
The forest holds its secrets tight.
With canopies reaching toward the sky,
And roots that spread both deep and wide.
For those who call the woodland home,
Its fate is closely intertwined.
A source of life, a place to roam,
A shelter in a world unkind.
But inequality runs deep,
In research of the forest realm.
A lack of access, a dearth of data,
Leaves many communities overwhelmed.
To bridge the gap, a pathway forms,
A cyber-innovated plan.
With global partnerships, new norms,
To lend a helping hand.
A dynamic framework, data shared,
A chance for all to lead.
To foster growth and show we cared,
For the nature we all need.
Through this, a brighter future dawns,
For those who dwell beneath the trees.
A world where all can thrive and find,
The beauty in the forest breeze.
Social, economic, and political inclusion of all people, irrespective of age, sex, disability, race, ethnicity, and other status, constitutes a foundation for peace and prosperity for people and the planet(1). One area that has been largely ignored, however, is inequality in science, especially in forest research. For instance, a majority (74%) of total worldwide scientific publications in forestry and other fields of agriculture published between 2000 and 2018 are attributable to ten countries (United States, China, Brazil, India, Spain, Germany, Italy, Japan, Canada, and Australia). The rest of the world contributed only 26%, among which African countries all together contributed less than 5%(2).
In Africa, the extreme inequality in science(3) is manifested in several main areas. First, partly due to the high costs of STEM education, Africa has only 169 researchers per million inhabitants, less than 11% of the global average(4). Second, Africa accounts for only 1.3% of global research and development spending while international aid is not targeted at research and development with a high priority (4, 5). Third, African research institutes suffer from extremely limited data access and data capacity in general. For instance, university libraries in Africa, despite repeated efforts, are incapable of meeting the needs of faculty and students in research literature search and access. Although government agencies, institutes, and individual researchers have collected a number of useful datasets for forest research in Africa, foundable, accessible, interoperable, and reusable (FAIR) access to these datasets has been very limited(6).
The inequality in science has made significant impacts on communities in Africa and other Global South regions, as forest ecosystems are a critical node in an integrated systems approach to tackling global crises and achieving SDGs. Specifically, forest ecosystems provide crucial services such as mitigating greenhouse gas emissions and producing wood fuel and charcoal for 2.4 billion people in rural and indigenous communities(7). The lack of forest research, which is essential for the effective protection and conservation of global forest ecosystems, makes it more difficult for local communities to control deforestation, forest and soil degradation, as well as desertification. As these communities often rely on forests for food, energy, medicine, building materials, and natural barrier to infectious diseases(7), the inequality in forest research threatens people’s health and livelihoods, and can exacerbate the inequitable distribution of resources, with the wealthy having greater access to natural resources and opportunities for economic development and the poor trapped in poverty.
Here, we propose a pathway to mitigate the inequality in forest research through global partnership and cyber innovation. The cyber-innovated global partnerships address three common roots of this inequality: i) computing capacity. While many other disciplines have domain-specific science gateways that provide access to data and critical computational resources, computing capacity remains limited for forest research. From the catalog of nearly 632 gateways listed in the Science Gateways Community Institute (SGCI) catalog, there are only six gateways providing services related to the search term “forest”; ii) FAIR access to research data. Despite a substantial increase in the sharing of ground-sourced forest inventory (in situ) data in the past decade, less than 30% of in situ forest datasets are open-access and even less are FAIR(8); iii) global expert support. While existing collaborative networks (such as GFBI, AfriTRON, RAINFOR, ForestPlots.net) are promoting collaborative forest research at various scales, they are mostly exclusive to data contributors, and most under-represented researchers and other data users are left behind in the co-production of the knowledge to make it both globally consistent and locally relevant.
Our proposed cyber-innovated global partnerships consist of an integrated cyberinfrastructure (CI) and an inclusive global team of scientists and data contributors. With four core functions, the CI supports FAIR access to in situ forest inventory data, advanced analysis tools and research codes, as well as a secure team collaboration platform. The team collaborations produce end-products (e.g., research papers, open-source data products, information co-production, and team growth), which will feed back to increase the amount of research projects and resource to ensure healthy and sustainable ecosystem-wide growth. (Figure 1):

Figure 1: The cyberinfrastructure (CI) map and data governance
[Data Ingestion] The stringent and complex multi-tier and multi-source data-sharing policies in forest sciences pose an obstacle to collaborative forest research. The CI incorporates multiple data-sharing policies – pre-defined by data contributors of local raw datasets – in a dynamic system so that these policies are enforced throughout the data lifecycle. The CI first collects local raw forest inventory data from around the world, and converts them into standard global datasets after error-checking and harmonization. According to the data-sharing policies pre-defined by data contributors, the CI distributes these global datasets to a number of ongoing research projects in the system. This data ingestion service enables data contributors to register and contribute data resources in the proposed CI, with a customizable data processing tool designed for both streaming and batch data ingestion.
[Data Discovery and Publication] The data discovery service and associated web user interface enable data users in the CI to discover processed datasets that have been generated from the contributed datasets. Depending on the inferred privacy level of a particular processed dataset, users will either be able to visualize point-level, heat-map, and contour views on a map (for open datasets), or only basic metadata such as the data coverage and number of datasets used in generation (for restricted datasets). Research products and datasets that are generated by users from their analysis of these processed datasets can be made public with an associated DOI using the existing data publication process.
[Project Management] Projects in the proposed CI are the key research collaboration and access control mechanism. Users can gain access to the processed datasets by proposing a research project and requesting access to the necessary datasets. Users can create new projects either via the web user interface, or when selecting a processed dataset to use in a new project. When a processed dataset is requested, an approval request to all the requisite contributors is triggered based on dataset’s metadata. Contributors can review a project’s description before granting approval and will also be automatically added as collaborators on the project, following their approval. Once approval has been obtained from all the relevant contributors, a processed dataset will be added to the project storage.
[Data Analysis & Machine Learning Toolkit] The team-wide collaboration is supported by a secure project sandbox that utilizes machine learning (ML) models in a wide range of applications such as visual search, predictor variable importance ranking, forecasting, and anomaly detection. Data analysis of the processed datasets will be carried out in an interactive computing environment (e.g. R studio). The CI includes a ML toolkit which will make it easier for non-experts to understand and apply ML technologies such as classification, regression, prediction, and clustering to their research problems, so that users do not have to write any code. The ML toolkit will also include ready-to-use models for widely used ML algorithms such as Convolutional Neural Networks (CNN), Support Vector Machines (SVM), k-Means, Decision Trees, and Random Forests.
Security and Privacy
The CI supergroups can restrict access to those registered users who are also approved as members of the supergroup by an administrator. Next, access to each of the processed datasets will be controlled via a fine-grained access control policy based on pre-defined privacy levels. Existing security policy around project creation and team-member-based access will be employed to ensure projects are only accessible by authorized team members. The CI’s plugin infrastructure supports the definition of custom event-handlers for various project-related events such as project creation and project file addition. Custom event handlers will be developed to implement the approval chain required for access to a processed dataset in a project. Specifically, an email will be generation for each requisite data contributor along with a secure URL that the contributor can visit to review the project’s description, approve, or disapprove the dataset’s inclusion, and provide optional comments. Only after approval by all requisite data contributors will the processed dataset be made available in the project’s file storage.
Integrity, Provenance, Transparency, Reproducibility, and Usability
Provenance will be captured for both the raw datasets and the processed data products in the CI and serialized as metadata attached to these files. Checksums will also be generated to enable future data validation as needed. The Schema.org metadata schema will be used to encode the file metadata and will include the data contributor information, contributor-specified data descriptions, as well as any derived spatio-temporal extents. Metadata on processed data products will be retained when copied to a project’s file storage, along with the necessary checksums. Generated data products, the corresponding analysis code and ML models, and their associated metadata can be published with an associated DOI and persistent URL to support discovery and reproducibility. Resource-intensive simulations can be off-loaded to high-performance computing (HPC) resources. Web access to projects, and scalable, containerized tools will ensure that users across the world have low-barrier access to research data contribution and usage.
Knowledge Co-production Among Stakeholders
Knowledge co-production will feed back to the CI to ensure a healthy and sustainable growth. In forest sciences, the CI will connect forest inventory personnel and policy makers under one roof, so that forest inventories funded by carbon initiatives such as REDD+ can be incorporated into forest tree monitoring. Meanwhile, the severe shortage of experts and facilities, especially from indigenous regions and in low-income countries, poses a major hurdle for global monitoring of forest trees(9). The education and training from this research project, especially with indigenous communities, can bring tangible benefits to global forest tree monitoring while improving local economies as well. Furthermore, the collective human experiences of rural communities embedded within these forested landscapes have strong ties to surrounding forest types. From the Sitka spruce—western hemlock forests in the Pacific Northwest to the tropical rainforests in Amazonia, the change of native forests induced by climate change is threatening the customs, identities, and culture of indigenous and other local communities, jeopardizing the non-timber forest products supply and overall environmental justice(10). The multi-stakeholder team in the proposed CI co-produces knowledge and policies on climate-resilient forest management and conservation, which will bring tangible benefits to help local communities adapt their cultural norms and relationships to the changes in surrounding forests.
Measurable Outcomes
With the proposed cyber-innovated global partnership model, we have established Science-i as a global research metaverse that seeks to accelerate forest science by empowering underrepresented communities in global research and knowledge co-production. The beta testing site was online in April 2022. To this date, there are more than 320 members registered from 55 countries (13 from Africa, 8 from Asia, 22 from Europe, 2 from Oceania, 3 from North America, and 6 from South America). The global member team of Science-I cover a broad range of expertise areas, including applied ecology (175), forestry (163), computer science (12), economics (8), anthropology (4), and many more. 55 members are female, and 113 members are from developing countries. Based on this diverse and comprehensive global network team, who contributed more than 200 in situ forest inventory datasets, we have compiled a ground-sourced global forest inventory database (GFI-3D), which consists of 1.5 million sample plots distributed across the global forest range (Figure 2).
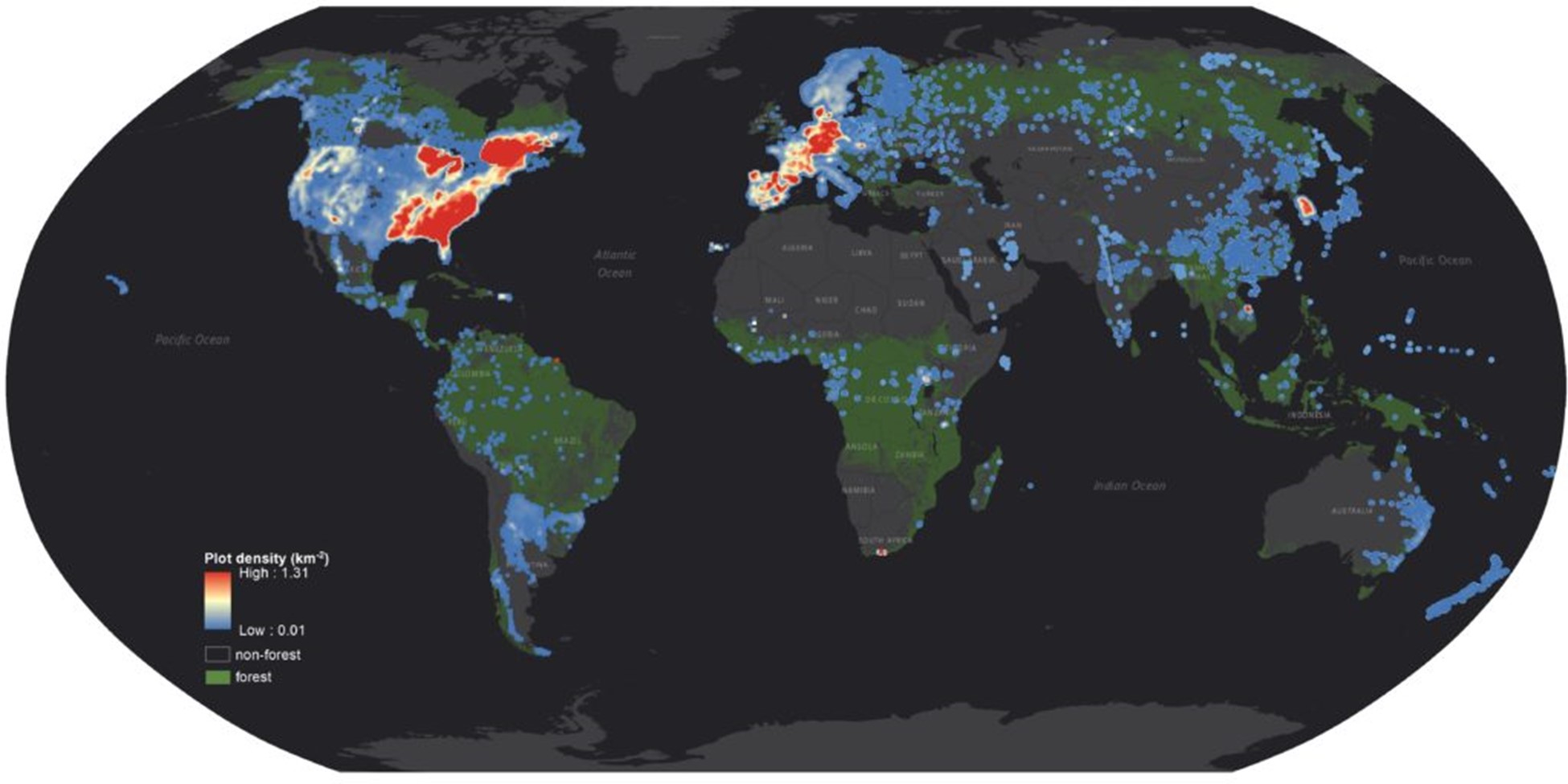 Figure 2: GFI-3D consists of in situ tree-level measurement of 1.5 million forest sample plots. Each plot is underpinned by exhaustive community-wide tree survey records including tree species, status, expansion factor(27), measurement year, diameter-at-breast-height, as well as key plot-level attributes. Global forest extent is indicated with green shading.
Figure 2: GFI-3D consists of in situ tree-level measurement of 1.5 million forest sample plots. Each plot is underpinned by exhaustive community-wide tree survey records including tree species, status, expansion factor(27), measurement year, diameter-at-breast-height, as well as key plot-level attributes. Global forest extent is indicated with green shading.
Utilizing the foregoing global database and a prototype CI based our proposed cyber-innovated global partnership model, Science-i is currently supporting 14 forest research projects(12), spanning a broad spectrum of subject areas, including biogeography, macroecology, forestry, ecological modeling, and microbial ecology. Among these ongoing projects, ten are led by female principal investigators. Except for one project, all studies are led by graduate students, postdoctoral researchers, or other early-career scientists. It is particularly noteworthy that this article was developed with Science-i. From October 2022 to April 2023, the service team of Science-i have hosted a series of global webinars (Globinar) in which invited guest speakers and hundreds of participants engaged in inclusive and constructive discussions on reducing inequality in forest research. Using the CI of Science-i, every single author was able to contribute to this article, throughout the entire life cycle of this project, from conceiving the idea to proofreading the text.
Summary
The cyberinfrastructure (CI) described here innovates global partnership to reduce the inequality in forest research with user-specific customizable data-sharing policies enforced through the data lifecycle, as well as transparent real-time worldwide co-production and cross-validation through inclusion of data contributors in the research lifecycle. The CI will also significantly reduce the complexity of connecting workflows to the requisite data and technologies. The CI engages under-represented communities, including undergraduate indigenous researchers, by granting them access to global research data, toolkits for data analyses, and a platform to co-produce and cross-validate research findings with experts worldwide. These benefits also extend to forest landowners and conservation/restoration professionals, for building global communities to find solutions that will significantly impact the future of our forest ecosystems worldwide for climate change mitigation and poverty alleviation. The reduced inequality will also improve workforce diversity in forest research, which in turn increases scientific outputs, as mounting evidence supports that diversity of scientists underpins the quality and productivity of scientific research, and elevates our ability to translate science to society and policy(13).
References
1. UN General Assembly, “Transforming our world: the 2030 Agenda for Sustainable Development,” (United Nations, New York, USA, 2015).
2. NSF, NSB, “Publications Output: U.S. Trends and International
Comparisons,” (National Science Board, 2021).
3. J.-P. O. d. Sardan, Promouvoir la recherche face à la consultance. Autour de l’expérience du lasdel (Niger-Bénin). Cahiers d’études africaines 51, 511-528 (2011).
4. K. Hüfner, in A concise encyclopedia of the United Nations. (Brill Nijhoff, 2000), pp. 557-560.
5. K. Marou Sama, R. d’Aiglepierre, S. Botton, Recherches africaines et rôles de l’aide internationale: le cas des sciences sociales. Rapports techniques, (2019).
6. C. Doumenge, F. Palla, I. Madzous, G. Ludovic. (OFAC, 2021).
7. FAO, UNEP, “The State of the World’s Forests 2020. Forests, biodiversity and people,” (United Nations, Rome, Italy, 2020).
8. J. Liang, J. G. P. Gamarra, The importance of sharing global forest data in a world of crises. Scientific Data 7, 424 (2020).
9. E. O. Wilson, A Global Biodiversity Map. Science 289, 2279-2279 (2000).
10. J. Fleetwood, Social justice, food loss, and the sustainable development goals in the era of COVID-19. Sustainability 12, 5027 (2020).
11. J. Liang et al., Co-limitation towards lower latitudes shapes global forest diversity gradients. Nature Ecology & Evolution 8, 10.1038/s41559-41022-01831-x (2022).
12. Science-i team. Science-i Ongoing Research Projects, <https://science-i.org/groups/> (Accessed April 2023).
13. J. L. Graves, M. Kearney, G. Barabino, S. Malcom, Inequality in science and the case for a new agenda. Proceedings of the National Academy of Sciences 119, e2117831119 (2022).